4.15. Duplicaten zoeken en samenvoegen
Deze tool detecteert dubbele entiteiten en stelt u in staat deze samen te voegen.
Beschrijving
Deze tool detecteert dubbele entiteiten, analyseert ze en biedt de mogelijkheid om ze automatisch of handmatig samen te voegen als het echte duplicaten zijn, of om ze te bevestigen als niet-duplicaten als dat niet het geval is.
Er zijn 4 manieren om duplicaten samen te voegen, elk manier wordt op deze pagina beschreven.
- Globale zoekopdracht in het gehele genealogiebestand
- Automatische detectie telkens wanneer een entiteit wordt gewijzigd
- Handmatige samenvoeging waarbij de gebruiker twee entiteiten selecteert om samen te voegen
- Slepen-en-neerzetten van entiteiten tussen genealogiebestanden
Bij elk van deze methoden wordt hetzelfde venster gebruikt.
De tool Duplicaten Samenvoegen bestaat uit drie onderdelen:
- Selectievenster voor entiteiten: hier kies je welke entiteiten je wilt controleren op duplicaten.
- Samenvoegvenster: hier worden alle potentiële duplicaten getoond en kun je analyseren of ze moeten worden samengevoegd.
- Lijst van niet-duplicaten: hier worden je bevestigingen opgeslagen dat twee entiteiten géén duplicaten zijn.
Overeenkomstscore (Resemblance Score)
Het is vaak lastig om met absolute zekerheid vast te stellen of twee entiteiten duplicaten zijn of niet. Zelfs een mens kan daar moeite mee hebben.
Bijvoorbeeld, twee personen met exact dezelfde achternaam, voornaam en geboortedatum zouden als duplicaat kunnen worden beschouwd. Maar in de praktijk kunnen data ontbreken of slechts bij benadering kloppen, kunnen voornamen in een andere volgorde staan of afgekort zijn, enz.
Daarom gebruikt Ancestris een **overeenkomstscore**. Hoe meer informatie overeenkomt, hoe groter de kans dat twee entiteiten duplicaten zijn.
- De score varieert van negatieve waarden tot hoge positieve waarden en wordt uitgedrukt als een percentage (ook al kan de score hoger zijn dan 100%).
- Ancestris toont de potentiële duplicaten in aflopende volgorde van overeenkomstscore.
- Het is aan jou om te beslissen of je ze samenvoegt of negeert.
Let op: Ancestris kan soms onnodige duplicaten tonen of juist echte duplicaten missen. Onze excuses als de detectie niet perfect is! Laat het ons weten als je verbeteringen opmerkt.
=====================================================================
Deze tool geeft de lijst met entiteiten die waarschijnlijk duplicaten zijn, van het meest zekere paar duplicaten tot het minst zekere paar duplicaten, per entiteitscategorie. Voor elk paar vergelijkbare entiteiten geeft Ancestris u een overeenkomstpercentage.
Deze tool geeft geen 100% zekere duplicaten. Zelfs een mens kan soms moeite hebben om te bevestigen dat twee individuen hetzelfde zijn of zeker niet.
Men zou natuurlijk kunnen stoppen met te zeggen dat twee personen met exact dezelfde achternaam, voornaam en geboortedatum duplicaten zijn. Maar een van deze stukjes informatie kan ontbreken voor een van de individuen, of het kan onnauwkeurig zijn.
Wat u van Ancestris verwacht, is u te waarschuwen en te zeggen:" Het is niet zeker, maar gezien de overeenkomsten in de informatie tussen deze twee personen, kunnen het duplicaten zijn. En dit is het niveau van vertrouwen dat ze zijn ". Dan is het aan u om te beslissen.
Dat is het doel van dit hulpmiddel.
Gebruik
Het samenvoegen van dubbelen werkt in twee stappen.
Eerst geeft u de detectiecriteria op en vervolgens kiest u hoe u duplicaten wilt samenvoegen .
Globale zoekopdracht
Automatische detectie
Handmatige samenvoeging
Slepen en neerzetten van de ene stamboom naar de andere
Detectie criteria
Wanneer de tool wordt gestart, wordt het selectievenster voor criteria weergegeven.
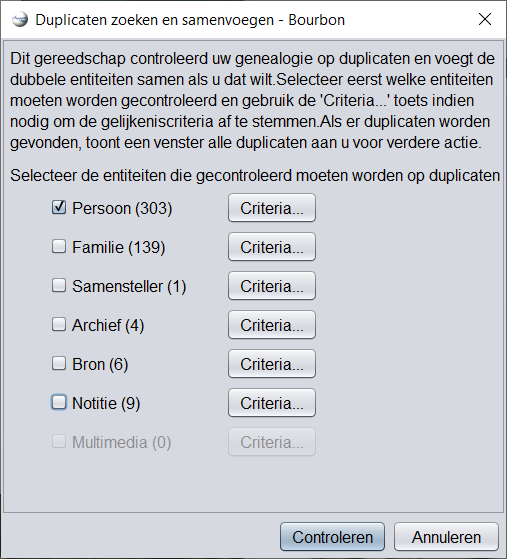
Vink de entiteiten aan waarvan u naar duplicaten wilt zoeken. (Hier alleen personen)
Alleen de entiteiten die aanwezig zijn in het Gedcom-bestand zijn beschikbaar. Aangezien er in het bovenstaande voorbeeld geen multimedia-entiteiten zijn, is de bijbehorende knop Criteria niet beschikbaar.
Controleer vervolgens één voor één de detectiecriteria voor elke entiteitscategorie.
De meest geavanceerde criteria zijn die van individuen:
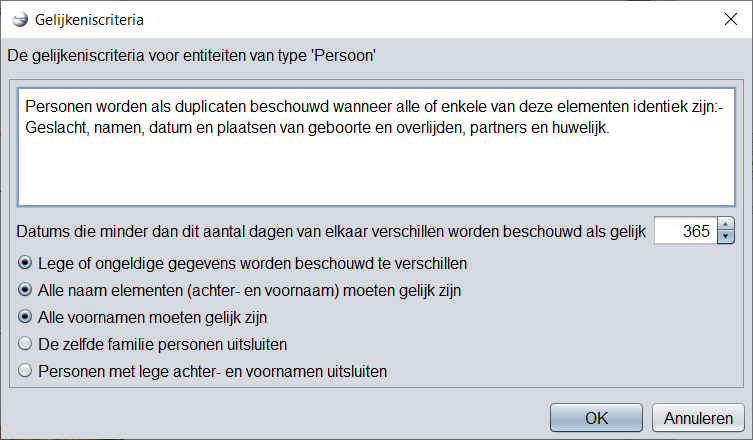
De 6 criteria zijn als volgt.
Identieke data
"Datums die minder dan xxx dagen met alkaar verschillen"
Wanneer worden twee datums als identiek beschouwd? Wanneer hun verschil in aantal dagen dichtbij of nul is.
- Als u bijvoorbeeld 365 dagen aangeeft, dus 1 jaar, zijn twee datums gelijk als hun verschil minder dan een jaar is.
- Als u 30 dagen aangeeft, zijn twee datums gelijk als ze minder dan een maand verschillen.
Lege of ongeldige datums
Als een bekende datum wordt vergeleken met een onbekende datum, beschouwt Ancestris deze als verschillend.
Naam elementen
Forceert dat alle elementen van de naam identiek zijn. Omgekeerd kan het identiek zijn als slechts enkele elementen van de naam identiek zijn.
Voornamen
Forceert dat alle voornamen identiek zijn. Omgekeerd kan het identiek zijn als slechts enkele voornamen identiek zijn.
Uitsluiting van personen uit dezelfde familie
Individuen uit dezelfde broer of zus of ouder-kindrelatie worden niet vergeleken.
Uitsluiting van personen zonder voor- of achternaam
Personen zonder voor- of achternaam worden niet vergeleken.
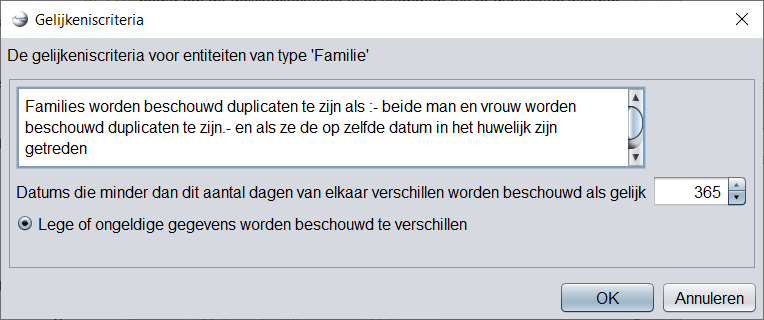
Andere entiteiten:
De criteria voor andere entiteiten zijn een onderdeel van deze criteria of ze kunnen niet worden gewijzigd.
Voorbeelden:
 |
 |
 |
 |
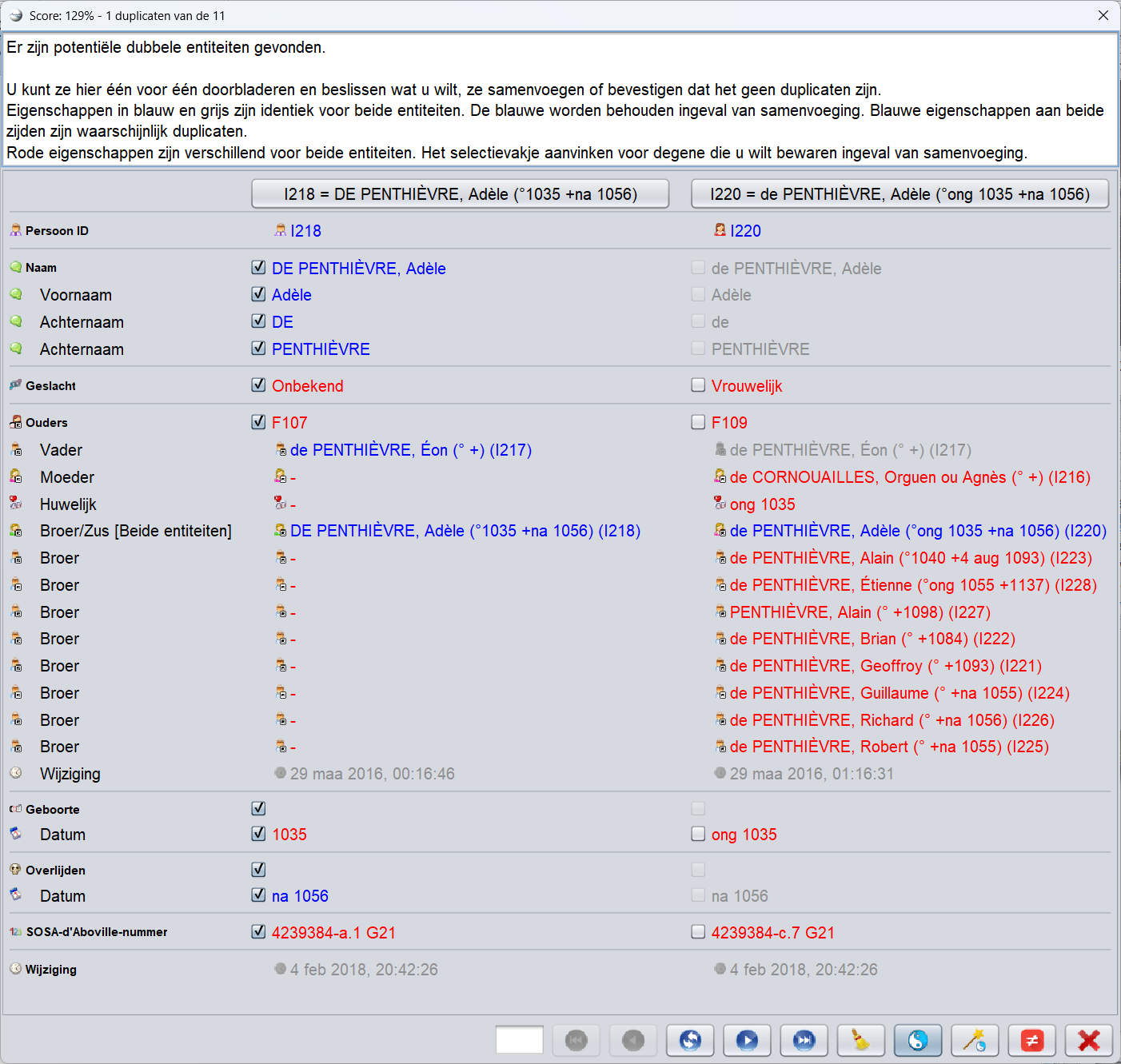
Het samenvoeg-venster
Na het starten van het zoeken naar duplicaten verschijnt het volgende venster.
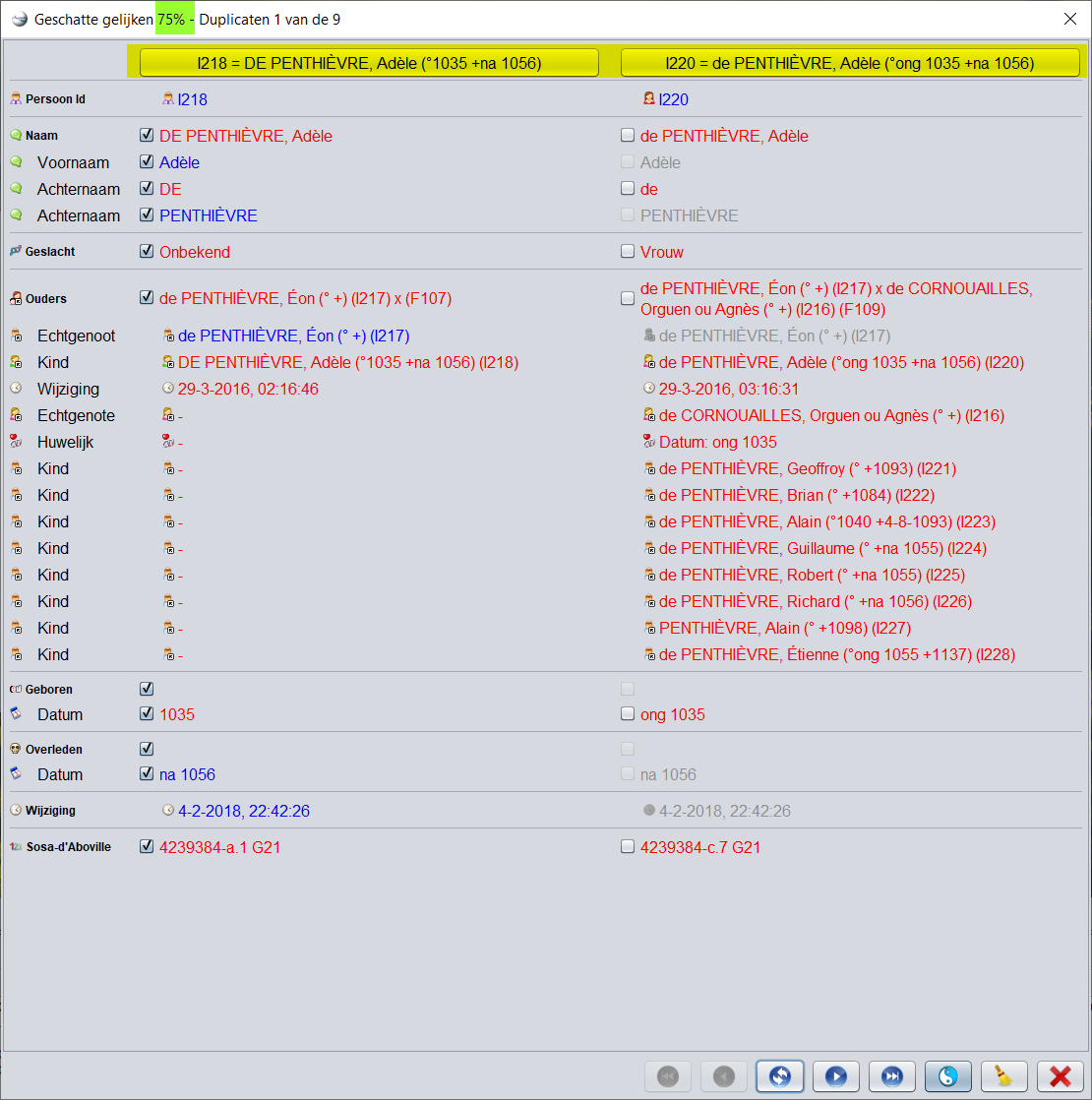
Venster
De titel van het venster geeft het weergegeven dubbele paarnummer aan en het percentage vertrouwen (in groen) dat de twee entiteiten van dit paar in feite hetzelfde zijn en daarom moeten worden samengevoegd.
De twee entiteiten van het veronderstelde dubbele paar staan in de twee kolommen.
Met een knop (in geel) kunt u elk van de entiteiten in de editors selecteren voor meer details.
Voor elke eigenschap van de entiteiten toont het venster de waarden van de eigenschap voor elk van de twee entiteiten van het veronderstelde duplicaat.
-
In rood worden de waarden weergegeven die afwijken tussen de twee entiteiten..
-
Identieke waarden worden voor de linker entiteit in blauw weergegeven en in grijs voor de rechter entiteit.
Het doel van de vergelijking is om de rechtse entiteit samen te voegen in de linker (de linker blijft dan dus bestaan).
Hiertoe selecteren de selectievakjes de informatie van elke entiteit die moet worden bewaard na het samenvoegen.
De knoppen onderaan navigeren binnen de dubbele paren, voegt ze samen of negeert ze.
werkbalk met knoppen

Knop 1: Ga naar de eerste dubbele
Geeft de eerste dubbele weer in de volgorde van de betrouwbaarheidsindex, dwz de meest waarschijnlijke dubbele.
Knop 1: Ga naar de vorige dubbele
Geeft het vorige duplicaat weer.
Knop 3: Wissel linker- en rechter- entiteiten
Verwissel de linker en rechter entiteiten om de twee entiteiten aan de linkerkant samen te voegen. Dit is handig als de meeste informatie die moet worden bewaard na het samenvoegen zich aan de rechterkant bevindt.
Knop 4: Ga naar de volgende dubbele
Geeft het volgende duplicaat weer.
Knop 5: Ga naar de laatste dubbele
Geeft het laatste duplicaat in de betrouwbaarheidsindex weer, dus het minst waarschijnlijke duplicaat.
Verwijder dubbele knop
Verwijdert de potentiële dubbele uit de weergegeven lijst.
Als de zoekopdracht naar dubbelen opnieuw wordt gestart, wordt deze (verwijderde) wel opnieuw weergegeven.
Knop 8: Sluit het venster
Sluit het venster.
Samenvoegen
Door op de knop Samenvoegen te klikken, wordt de rechts aangevinkte informatie toegevoegd aan de linker entiteit, daarna wordt de rechter entiteit verwijderd uit de Gedcom.
Voor informatie die maar één keer kan bestaan (bijv. geboorte), is het alleen mogelijk om de informatie van een van de twee entiteiten te behouden.
Zodra het samenvoegen is voltooid, geeft het venster hetzelfde duplicaat weer met het resultaat van de samenvoeging, zodat u kunt controleren of alles is bewaard zoals u wilde.
U kunt dan doorgaan naar het volgende duplicaat.
Aanpassingen
De personalisatie-elementen zijn de criteria.
De gebruikte criteria worden voor de volgende keer opgeslagen.
Er is geen andere aanpassingsmogelijkheid.